
Κείμενα, φωτογραφίες και βίντεο φτιαγμένα από διάφορες υπηρεσίες τεχνητής νοημοσύνης κατακλύζουν τις οθόνες μας και κανείς δεν νιώθει άνετα.
Εφόσον οι μετρήσεις είναι ακριβείς, χρειάστηκαν περίπου τρία χρόνια για να πάρει η τεχνητή νοημοσύνη το πάνω χέρι στην παραγωγή και διάθεση δεδομένων στο διαδίκτυο.
Θεωρούμε ότι το χρονικό σημείο μηδέν είναι ο Νοέμβριος του 2022, όταν το ChatGPT έγινε διαθέσιμο στο ευρύ κοινό, αν και μέχρι εκείνη τη στιγμή είχαν εμφανιστεί πολλές υπηρεσίες στον τομέα της δημιουργικής τεχνητής νοημοσύνης.
ChatGPT, Gemini, Claude, DeepSeek, Perplexity και χιλιάδες ακόμα μοντέλα και υπηρεσίες, δημιουργούν καθημερινά -κατόπιν παραγγελίας των ανθρώπων που με ενθουσιασμό τις χρησιμοποιούν- τεράστιο όγκο δεδομένων κάθε μορφής. Κείμενα, φωτογραφίες, βίντεο, κώδικας βγαίνουν με καταιγιστικό ρυθμό και με διάφορους τρόπους καταλήγουν στις οθόνες μας, είτε επειδή το ζητήσαμε είτε επειδή εμφανίζεται στη ροή ενημερώσεών μας σε ένα μέσο κοινωνικής δικτύωσης.
Καλώς ήρθατε σε έναν κόσμο συνθετικών δεδομένων.
Δεδομένα χαμηλής διατροφικής αξίας
Ο ορισμός είναι απλός, τα συνθετικά δεδομένα είναι ο,τιδήποτε παράγεται από την τεχνητή νοημοσύνη. Σε αντιδιαστολή, έχουμε τα ανθρωπογενή δεδομένα και επί χιλιάδες χρόνια, το είδος μας είχε το μονοπώλιο στη μετάδοση της γνώσης από γενιά σε γενιά. Αυτό το μονοπώλιο καταργήσαμε εκουσίως με την εμφάνιση της δημιουργικής και της γενικής χρήσης τεχνητής νοημοσύνης.

Τα γλωσσικά μοντέλα έχουν πια «διαβάσει» ό,τι έχει δημιουργηθεί από τον άνθρωπο αλλά κάπως θα πρέπει να συνεχίζεται η εξέλιξή τους. Η ιδέα για χρήση των συνθετικών δεδομένων ακούγεται λογική. Αν οι άνθρωποι μαθαίνουν από άλλους ανθρώπους γιατί να μη συμβαίνει κάτι ανάλογο για τις μηχανές;
Μόνο που οι δοκιμές δείχνουν ότι τα πράγματα δεν είναι έτσι όπως τα θέλουμε.
Όταν ένα γλωσσικό μοντέλο εκπαιδεύεται με βάση συνθετικά δεδομένα, χάνει σταδιακά σε πολυπλοκότητα. Τα συνθετικά δεδομένα είναι ομοιογενή, έχουν πιο απλή δομή σε σχέση με τα ανθρωπογενή δεδομένα και έχουν μια τάση να κινούνται προς τον μέσο όρο.
Αν τα ανθρωπογενή δεδομένα είναι κεφτεδάκια που φτιάχνουμε στο σπίτι μας ,τα συνθετικά είναι τα μπιφτέκια μιας αλυσίδας fast-food. Τα πρώτα δεν είναι πανομοιότυπα μεταξύ τους, τα δεύτερα είναι. Διατροφικώς, τα πρώτα τείνουν να είναι καλύτερα από τα δεύτερα.
Κατ’ αναλογία, τα συνθετικά δεδομένα είναι πιο «φτωχά», δεν περιέχουν δημιουργικές εκφράσεις, νεολογισμούς και, γενικά, τις μικρολεπτομέρειες που διαφοροποιούν τον λόγο από άνθρωπο σε άνθρωπο.
Καθώς έχουν την τάση να κινούνται προς τον μέσο όρο, αναπαράγουν και τον μέσο όρο των προκαταλήψεων, οπότε στην εκπαίδευση των γλωσσικών μοντέλων των επόμενων γενιών οι ίδιες προκαταλήψεις θα διαιωνίζονται. Δεν είναι ότι οι ανθρώπινες προκαταλήψεις είναι καλύτερες, απλώς υπάρχουν διαφορές μεταξύ των ανθρώπων που αναπτύσσουν ή «εκπαιδεύουν» τα γλωσσικά μοντέλα. Αλλιώς βλέπει τον κόσμο ένας Αμερικανός, αλλιώς ένας Ασιάτης, για παράδειγμα και οι προκαταλήψεις του πρώτου δεν συμπίπτουν με εκείνες του δεύτερου. Αυτή η ποικιλομορφία (ακόμα και η αρνητική της πλευρά, όπως εκδηλώνεται με διάφορες προκαταλήψεις) χάνεται όταν το γλωσσικό μοντέλο αναλαμβάνει τον ρόλο το «δασκάλου» για τα μοντέλα της επόμενης γενιάς.
Κάποιος που εξαρτά τη διατροφή του αποκλειστικά από τα μπιφτέκια ενός fast-food είναι αρκετά πιθανό ότι θα αντιμετωπίσει προβλήματα υγείας. Κατ’ αναλογία προβλήματα θα αντιμετωπίσει και το γλωσσικό μοντέλο που εκπαιδεύεται μόνο με συνθετικά δεδομένα, αφού από την υπερβολική ομοιογένεια στο τέλος θα παράγει αποτελέσματα που θα χαρακτηρίζονται από τόση ομοιογένεια που θα είναι, τελικώς, άχρηστα για τον άνθρωπο που τα παρήγγειλε.
Υπάρχουν κάποιες προσεγγίσεις που προσπαθούν να απαντήσουν σε αυτή την πρόκληση. Η δημιουργία συνθετικών δεδομένων με τρόπο που να μοιάζει με τον ανθρώπινο, ακούγεται ως μια καλή προσέγγιση. Βεβαίως, εύκολα το λες, δύσκολα το κάνεις. Για παράδειγμα, η Anthropic μιλάει για «Συνταγματική Τεχνητή Νοημοσύνη» (Constitutional AI) όπου σε πρώτη φάση το γλωσσικό μοντέλο λαμβάνει ένα σύνολο αρχών τις οποίες οφείλει να τηρεί – ένα είδος Συντάγματος δηλαδή. Αν σας θυμίζει τους τρεις νόμους ρομποτικής που είχε περιγράψει ο Ισάακ Ασίμοφ, είστε σε καλό δρόμο.
Με βάση αυτές τις αρχές, το γλωσσικό μοντέλο φτάνει στο σημείο να αξιολογεί τις απαντήσεις του αυτόματα. Για να φτάσει εκεί, ξεκινάει από ένα κατώτερο επίπεδο, όπου υπάρχει ανθρώπινη επίβλεψη στη διαδικασία εκμάθησης. Ακολούθως, ένα άλλο μοντέλο που λειτουργεί ως ανεξάρτητος και ουδέτερος παρατηρητής εξετάζει κατά πόσο οι απαντήσεις τηρούν τις αρχές του «Συντάγματος» και, εφόσον το γλωσσικό μοντέλο – μαθητής περάσει με επιτυχία τις δοκιμασίες προχωρά, πια, αυτόνομα ως «πολίτης» που υπακούει στους κανόνες.
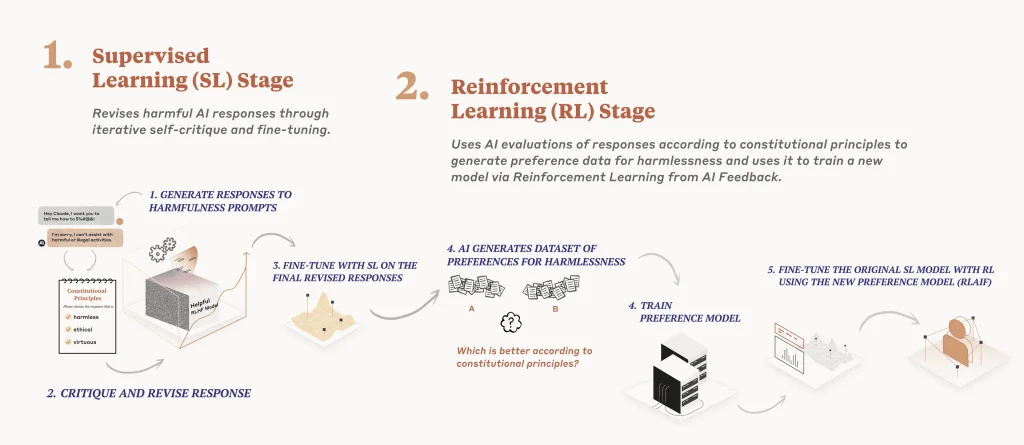
Οι οποίοι κανόνες του «Συντάγματος» της Anthropic έχουν θεσπιστεί με βάση κείμενα που αντανακλούν κυρίως δυτικές αξίες. Αυτή η προσέγγιση είναι καλή διότι εμπεριέχει ασφάλεια (για παράδειγμα, το μοντέλο δεν θα μας πει πώς θα ανατρέψουμε με όπλα την κυβέρνηση της χώρας μας και θα μας προτείνει να φτιάξουμε ένα πολιτικό κόμμα και να επιδιώξουμε την αλλαγή μέσω εκλογών) αλλά δεν έχουν όλοι τις ίδιες αξίες. Πολλές κοινωνίες δίνουν τεράστια σημασία στον σεβασμό στους μεγαλύτερους, σε άλλες υπάρχουν βαθιά ριζωμένες θρησκευτικές παραδόσεις και σε άλλες το τι είναι ελεύθερη έκφραση μπορεί να μας κάνει να διαφωνήσουμε. Είναι μάλλον δύσκολο να βρούμε, τελικά, ένα «Σύνταγμα» στο οποίο θα συμφωνήσουμε όλοι, όμως ακόμα και αν δεχθούμε ότι υπάρχουν 10 ισχυρά γλωσσικά μοντέλα με ισάριθμο κατάλογο κανόνων, είναι δύσκολο να ξεφύγουμε από την ομοιομορφία που δημιουργείται από την επικράτηση των συνθετικών δεδομένων. Μπορεί η ομοιομορφία να μην είναι οικουμενική αλλά θα έχουμε δέκα από αυτές με κάποιες παραλλαγές μεταξύ τους.
Εφιαλτική ομοιομορφία
Η αρχιτεκτονική έχει ουκ ολίγα παραδείγματα δημιουργιών που δίχασαν τον κόσμο και το μουσείο Guggenheim είναι μια εξαιρετική περίπτωση αρχιτεκτονικής δημιουργίας που όταν κατασκευάστηκε συνάντησε την έντονη αποδοκιμασία.

Το χαρακτήρισαν «τεράστιο γκαράζ», «γιγαντιαίο τιρμπουσόν», «τεράστια φόρμα για γλυκά», «ανάποδο μπολ», «υπερμεγέθη φραντζόλα», «λεκάνη χωρίς λαβές». Καθόλου κολακευτικά σχόλια.
Έντονα αρνητική ήταν η υποδοχή που επιφυλάχθηκε και για το Κέντρο Pompidou στο Παρίσι, με τη Le Monde να μιλάει για τον «βιασμό του Παρισιού» και τους Παριζιάνους να του δίνουν το παρατσούκλι «Η Nottre Dame των σωληνώσεων».

Τα δύο κτίρια απέχουν μεταξύ τους 20 χρόνια αλλά ένα από τα (πολλά) στοιχεία που τα συνδέουν είναι ότι δεν σχεδιαστεί με τον μέσο όρο κατά νου. Ένα μοντέλο τεχνητής νοημοσύνης που θα είχε εκπαιδευτεί με συνθετικά δεδομένα, θα ακολουθούσε τη μέση οδό, θα επέλεγε φόρμες που επικρατούν στο αστικό τοπίο και θα δημιουργούσε κτίρια που δεν θα ξεχώριζαν με τον τρόπο που ξεχωρίζουν το Guggenheim το Pompidou ή τα κτίρια του Gaudi.
Προγραμματιστές-ρομπότ, προγράμματα-ρομπότ
Είναι μάλλον βέβαιο ότι αν αφήσουμε τα συνθετικά δεδομένα να ορίσουν το αρχιτεκτονικό μας μέλλον, θα βυθιστούμε σε μια σούπα ομοιομορφίας αλλά τι γίνεται με έναν τομέα όπως είναι ο προγραμματισμός; Η ανάπτυξη εφαρμογών έχει σε γενικές γραμμές μια μεθοδολογία που δεν αφήνει πολλά περιθώρια για προσεγγίσεις ανάλογες με εκείνες που επέδειξε ο Gaudi, οπότε γιατί να μην αφήσουμε τις μηχανές να γράψουν τις εφαρμογές μας κατά παραγγελία;
Μιλάμε, βεβαίως, θεωρητικά αλλά ο κώδικας παράγεται από συστήματα τεχνητής νοημοσύνης που έχουν εκπαιδευτεί για αυτό τον σκοπό με κώδικα από συστήματα παλαιότερης γενιάς, δεν θα είναι κατ’ ανάγκη καλύτερος από τον κώδικα των -ανθρώπων- προγραμματιστών. Η τάση της ομοιογενοποίησης και η κυριαρχία του μέσου όρου θα δημιουργούσε «πολυλογάδικο» κώδικα με σειρές από if ή ατέρμονες αλληλουχίες βρόχων. Βέλτιστες αλλά όχι κατ’ ανάγκη ιδιαίτερα δημοφιλείς πρακτικές ασφαλείας ή πρακτικές που διακρίνονται από δεξιοτεχνία (διότι υπάρχει και τέτοια στον προγραμματισμό αντίθετα με ό,τι ίσως επικρατεί ως άποψη στους εκτός του χώρου) θα εξαφανίζονταν σταδιακά.
Ομοιομορφία σημαίνει ότι το κενό ασφαλείας που υπήρχε σε μια εφαρμογή μπορεί να επανεμφανίζεται σε άλλες, κάνοντας τη δουλειά των κυβερνοεγκληματιών πιο εύκολη και των κυβερνοαστυνόμων πιο δύσκολη.
Στο τέλος, μοιραία οδηγούμαστε σε ατέρμονες γραμμές κώδικα, χωρίς κάποια βελτιστοποίηση. Σε ακόμα μεγαλύτερο βάθος χρόνου θα φτάνουμε σε κώδικα που θα είναι πια αδύνατο να συντηρηθεί ούτε από μηχανή ούτε από άνθρωπο.
Ενδεχομένως, όλο το σύστημα να καταρρεύσει τελικά εκ των έσω, επειδή ο κώδικας θα ήταν δυσνόητος (για όλους) και ευάλωτος (από πολλούς).
Όλα αυτά θα μπορούσαν να συμβούν τόσο βαθιά στον χρόνο που η εφαρμογή για την οποία γράφτηκε ο κώδικας θα είναι παρωχημένη, αλλά γιατί να μη συμβούν ταχύτερα, σε τρία, πέντε ή δέκα χρόνια;
Για την ώρα, η ανθρώπινη συμμετοχή στην ανάπτυξη και εξέλιξη των μοντέλων αποτελεί τη μόνη προσέγγιση που αντιμετωπίζει την πρόκληση των συνθετικών δεδομένων. Όμως, επειδή οι άνθρωποι έχουμε ένα μοναδικό ταλέντο στο να δυσκολεύουμε τα πράγματα, ο ενθουσιασμός μας για όσα δημιουργούν οι εφαρμογές γενικής και δημιουργικής τεχνητής νοημοσύνης είναι τέτοιος που με μεγάλη χαρά γεμίζουμε το διαδίκτυο με συνθετικά δεδομένα.
Υπάρχουν χρήστες σε διάφορα κοινωνικά δίκτυα που επαίρονται για την ανάθεση της συγγραφής δημοσιεύσεων σε γλωσσικά μοντέλα, λες και υπάρχει κάποιος διαγωνισμός σε εξέλιξη για το ποιος θα γράψει τα περισσότερα posts. Υπάρχουν λογαριασμοί που κάνουν υποτιθέμενες αναπαραστάσεις μαχών της αρχαιότητας, με Έλληνες και Πέρσες να ανταλλάσσουν προσβλητικές φράσεις στα αγγλικά, διότι το μοντέλο δεν μπορεί να «αντιληφθεί» τον αναχρονισμό και αυτός που έκανε την παραγγελία της αναπαράστασης δεν ενδιαφέρεται για τέτοιες λεπτομέρειες. Υπάρχει, τέλος, ουκ ολίγο υλικό που είναι αποτέλεσμα των παραισθήσεων από τις οποίες εξακολουθούν να πάσχουν τα γλωσσικά μοντέλα. Αν υπάρχει κάτι χειρότερο από την ομοιομορφία, αυτό είναι η ομοιομορφία με λάθη.
Μάλλον χρειαζόμαστε περισσότερο Guggenheim…




